数据结构概览
目录
数据结构研究的是数据的存储方式,算法研究的是解决问题的思路。数据结构与算法是相辅相成的。
常用存储结构
- 线性表,还可细分为顺序表(数组)、链表、栈和队列。
- 树结构,包括普通树,二叉树,二叉查找树等。
- 图存储结构。
线性表
线性表并不是一种具体的存储结构,它包含顺序存储结构和链式存储结构,是顺序表和链表的统称。
- 线性表是一种线性结构,它是由零个或多个数据元素构成的有限序列。
- 线性表的特征是在一个序列中,除了头尾元素,每个元素都有且只有一个直接前驱,有且只有一个直接后继,而序列头元素没有直接前驱,序列尾元素没有直接后继。
- 数据结构中常见的线性结构有数组、单链表、双链表、循环链表等。线性表中的元素为某种相同的抽象数据类型。
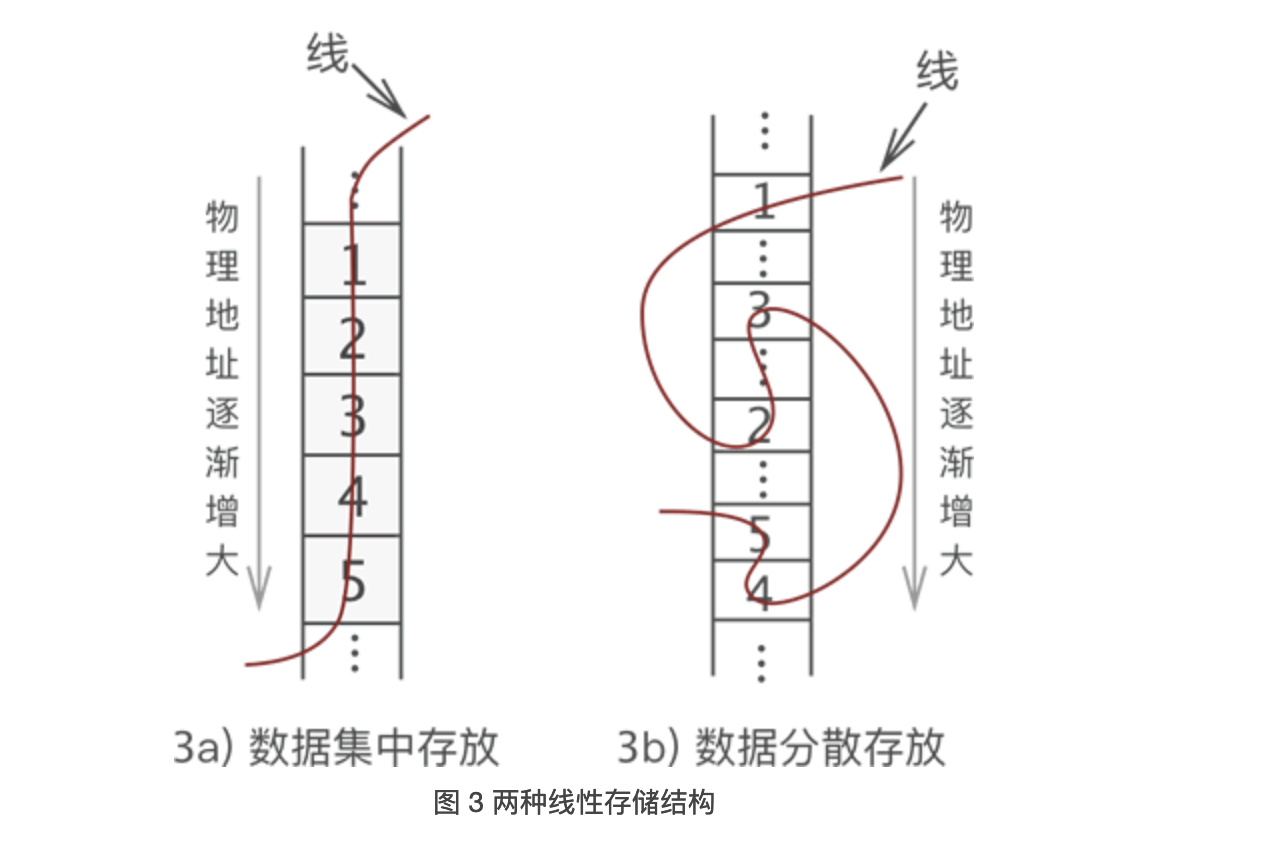
- 如图 3a) 所示,将数据依次存储在连续的整块物理空间中,这种存储结构称为顺序存储结构(简称顺序表,数组);
- 如图 3b) 所示,数据分散的存储在物理空间中,通过一根线保存着它们之间的逻辑关系,这种存储结构称为链式存储结构(简称链表)。
数组和矩阵(顺序表)
数组是一种连续存储线性结构,元素类型相同,大小相等,数组是多维的,通过使用整型索引值来访问他们的元素,数组尺寸不能改变。
链表
我们知道,使用顺序表(底层实现靠数组)时,需要提前申请一定大小的存储空间,这块存储空间的物理地址是连续的,链表则完全不同,使用链表存储数据时,是随用随申请,因此数据的存储位置是相互分离的,换句话说,数据的存储位置是随机的。
n个节点离散分配,彼此通过指针相连,每个节点只有一个前驱节点,每个节点只有一个后续节点,首节点没有前驱节点,尾节点没有后续节点。确定一个链表我们只需要头指针,通过头指针就可以把整个链表都能推出来。
哈希表(散列)
散列表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
栈和队列
数组和链表都是线性存储结构的基础,栈和队列都是线性存储结构的应用,栈和队列隶属于线性表,是特殊的线性表,因为它们对线性表中元素的进出做了明确的要求。
栈(LIFO)
- 使用数组实现的叫静态栈
- 使用链表实现的叫动态栈
栈(FIFO)
- 使用数组实现的叫静态队列
- 使用链表实现的叫动态队列
树存储结构
树存储结构适合存储具有“一对多”关系的数据。
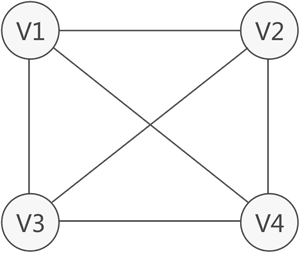
图存储结构
图存储结构适合存储具有“多对多”关系的数据。
和线性表,树的差异:
- 线性表中我们把数据元素叫元素,树中将数据元素叫结点,在图中数据元素,我们则称之为顶点(Vertex)。
- 线性表可以没有元素,称为空表;树中可以没有节点,称为空树;但是,在图中不允许没有顶点(有穷非空性)。
- 线性表中的各元素是线性关系,树中的各元素是层次关系,而图中各顶点的关系是用边来表示(边集可以为空)。
总结
我们知道,实际应用当中,我们经常使用的是查找和排序操作,这在我们的各种管理系统、数据库系统、操作系统等当中,十分常用。
- 数组 的下标寻址十分迅速,但计算机的内存是有限的,故数组的长度也是有限的,实际应用当中的数据往往十分庞大;而且无序数组的查找最坏情况需要遍历整个数组;后来人们提出了二分查找,二分查找要求数组的构造一定有序,二分法查找解决了普通数组查找复杂度过高的问题。任和一种数组无法解决的问题就是插入、删除操作比较复杂,因此,在一个增删查改比较频繁的数据结构中,数组不会被优先考虑
- 普通链表 由于它的结构特点被证明根本不适合进行查找
- 哈希表 是数组和链表的折中,同时它的设计依赖散列函数的设计,数组不能无限长、链表也不适合查找,所以也不适合大规模的查找
- 二叉查找树 因为可能退化成链表,同样不适合进行查找
- AVL树 是为了解决可能退化成链表问题,但是AVL树的旋转过程非常麻烦,因此插入和删除很慢,也就是构建AVL树比较麻烦
- 红黑树 是平衡二叉树和AVL树的折中,因此是比较合适的。集合类中的Map、关联数组具有较高的查询效率,它们的底层实现就是红黑树。
- 多路查找树 是大规模数据存储中,实现索引查询这样一个实际背景下,树节点存储的元素数量是有限的(如果元素数量非常多的话,查找就退化成节点内部的线性查找了),这样导致二叉查找树结构由于树的深度过大而造成磁盘I/O读写过于频繁,进而导致查询效率低下。
- B树 与自平衡二叉查找树不同,B树适用于读写相对大的数据块的存储系统,例如磁盘。它的应用是文件系统及部分非关系型数据库索引。
- B+树 在B树基础上,为叶子结点增加链表指针(B树+叶子有序链表),所有关键字都在叶子结点 中出现,非叶子结点作为叶子结点的索引;B+树总是到叶子结点才命中。通常用于关系型数据库(如Mysql)和操作系统的文件系统中。
- B*树 是B+树的变体,在B+树的非根和非叶子结点再增加指向兄弟的指针, 在B+树基础上,为非叶子结点也增加链表指针,将结点的最低利用率从1/2提高到2/3。 R树是用来做空间数据存储的树状数据结构。例如给地理位置,矩形和多边形这类多维数据建立索引。
- Trie树 是自然语言处理中最常用的数据结构,很多字符串处理任务都会用到。Trie树本身是一种有限状态自动机,还有很多变体。什么模式匹配、正则表达式,都与这有关。
针对大量数据,如果在内存中作业优先考虑红黑树(map,set之类多为RB-tree实现),如果在硬盘中作业优先考虑B系列树(B+, B, B)*