分布式ID
在复杂分布式系统中,往往需要对大量的数据和消息进行唯一标识。
概括下来,那业务系统对ID号的要求有哪些呢?
- 全局唯一:不能出现重复的ID号,既然是唯一标识,这是最基本的要求。
- 趋势递增:在MySQL InnoDB引擎中使用的是聚集索引,由于多数RDBMS使用B-tree的数据结构来存储索引数据,在主键的选择上面我们应该尽量使用有序的主键保证写入性能。
- 单调递增:保证下一个ID一定大于上一个ID,例如事务版本号、IM增量消息、排序等特殊需求。
- 信息安全:如果ID是连续的,恶意用户的扒取工作就非常容易做了,直接按照顺序下载指定URL即可;如果是订单号就更危险了,竞对可以直接知道我们一天的单量。所以在一些应用场景下,会需要ID无规则、不规则。
- 高可用:平均延迟和TP999延迟都要尽可能低;可用性5个9; 高QPS。
UUID
UUID是通用唯一识别码(Universally Unique Identifier)的缩写,开放软件基金会(OSF)规范定义了包括网卡MAC地址、时间戳、名字空间(Namespace)、随机或伪随机数、时序等元素。利用这些元素来生成UUID。
UUID是由128位二进制组成,一般转换成十六进制,然后用String表示。在java中有个UUID类,在他的注释中我们看见这里有4种不同的UUID的生成策略:
- randomly 基于随机数生成UUID,由于Java中的随机数是伪随机数,其重复的概率是可以被计算出来的。这个一般我们用下面的代码获取基于随机数的UUID:
- time-based 基于时间的UUID,这个一般是通过当前时间,随机数,和本地Mac地址来计算出来,自带的JDK包并没有这个算法的我们在一些UUIDUtil中,比如我们的log4j.core.util,会重新定义UUID的高位和低位。
- DCE security:DCE安全的UUID。
- name-based:基于名字的UUID,通过计算名字和名字空间的MD5来计算UUID。
UUID的优点
- 通过本地生成,没有经过网络I/O,性能较快
- 无序,无法预测他的生成顺序。(当然这个也是他的缺点之一)
UUID的缺点
- 128位二进制一般转换成36位的16进制,太长了只能用String存储,空间占用较多。
- 不能生成递增有序的数字
适用场景
UUID的适用场景为不担心过多的空间占用,以及不需要生成有递增趋势的数字。在Log4j里面他在UuidPatternConverter中加入了UUID来标识每一条日志。
数据库主键自增
大家对于唯一标识最容易想到的就是主键自增,这个也是我们最常用的方法。例如我们有个订单服务,那么把订单id设置为主键自增即可。
优点
简单方便,有序递增,方便排序和分页
缺点
- 分库分表会带来问题,需要进行改造。
- 并发性能不高,受限于数据库的性能。
- 简单递增容易被其他人猜测利用,比如你有一个用户服务用的递增,那么其他人可以根据分析注册的用户ID来得到当天你的服务有多少人注册,从而就能猜测出你这个服务当前的一个大概状况。
- 数据库宕机服务不可用。
适用场景
根据上面可以总结出来,当数据量不多,并发性能不高的时候这个很适合,比如一些to B的业务,商家注册这些,商家注册和用户注册不是一个数量级的,所以可以数据库主键递增。如果对顺序递增强依赖,那么也可以使用数据库主键自增。
Redis
Redis中有两个命令Incr,IncrBy,因为Redis是单线程的所以能保证原子性。
优点
性能比数据库好,能满足有序递增。
缺点
- 由于redis是内存的KV数据库,即使有AOF和RDB,但是依然会存在数据丢失,有可能会造成ID重复。
- 依赖于redis,redis要是不稳定,会影响ID生成。
适用
由于其性能比数据库好,但是有可能会出现ID重复和不稳定,这一块如果可以接受那么就可以使用。也适用于到了某个时间,比如每天都刷新ID,那么这个ID就需要重置,通过(Incr Today),每天都会从0开始加。
雪花算法-Snowflake
Snowflake是Twitter提出来的一个算法,其目的是生成一个64bit的整数
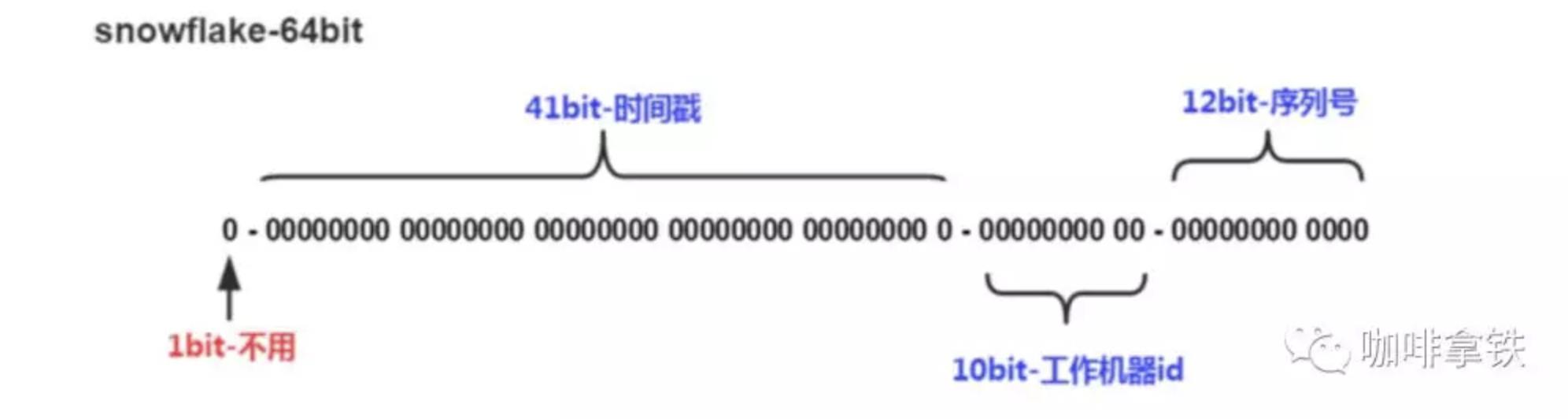
- 1bit:一般是符号位,不做处理
- 41bit:用来记录时间戳,这里可以记录69年,如果设置好起始时间比如今年是2018年,那么可以用到2089年,到时候怎么办?要是这个系统能用69年,我相信这个系统早都重构了好多次了。
- 10bit:10bit用来记录机器ID,总共可以记录1024台机器,一般用前5位代表数据中心,后面5位是某个数据中心的机器ID
- 12bit:循环位,用来对同一个毫秒之内产生不同的ID,12位可以最多记录4095个,也就是在同一个机器同一毫秒最多记录4095个,多余的需要进行等待下毫秒。
上面只是一个将64bit划分的标准,当然也不一定这么做,可以根据不同业务的具体场景来划分,比如下面给出一个业务场景:
- 服务目前QPS10万,预计几年之内会发展到百万。
- 当前机器三地部署,上海,北京,深圳都有。
- 当前机器10台左右,预计未来会增加至百台。
这个时候我们根据上面的场景可以再次合理的划分62bit,QPS几年之内会发展到百万,那么每毫秒就是千级的请求,目前10台机器那么每台机器承担百级的请求,为了保证扩展,后面的循环位可以限制到1024,也就是2^10,那么循环位10位就足够了。
机器三地部署我们可以用3bit总共8来表示机房位置,当前的机器10台,为了保证扩展到百台那么可以用7bit 128来表示,时间位依然是41bit,那么还剩下64-10-3-7-41-1 = 2bit,还剩下2bit可以用来进行扩展。
适用场景
当我们需要无序不能被猜测的ID,并且需要一定高性能,且需要long型,那么就可以使用我们雪花算法。比如常见的订单ID,用雪花算法别人就发猜测你每天的订单量是多少。
一个简单的Snowflake
| |
防止时钟回拨
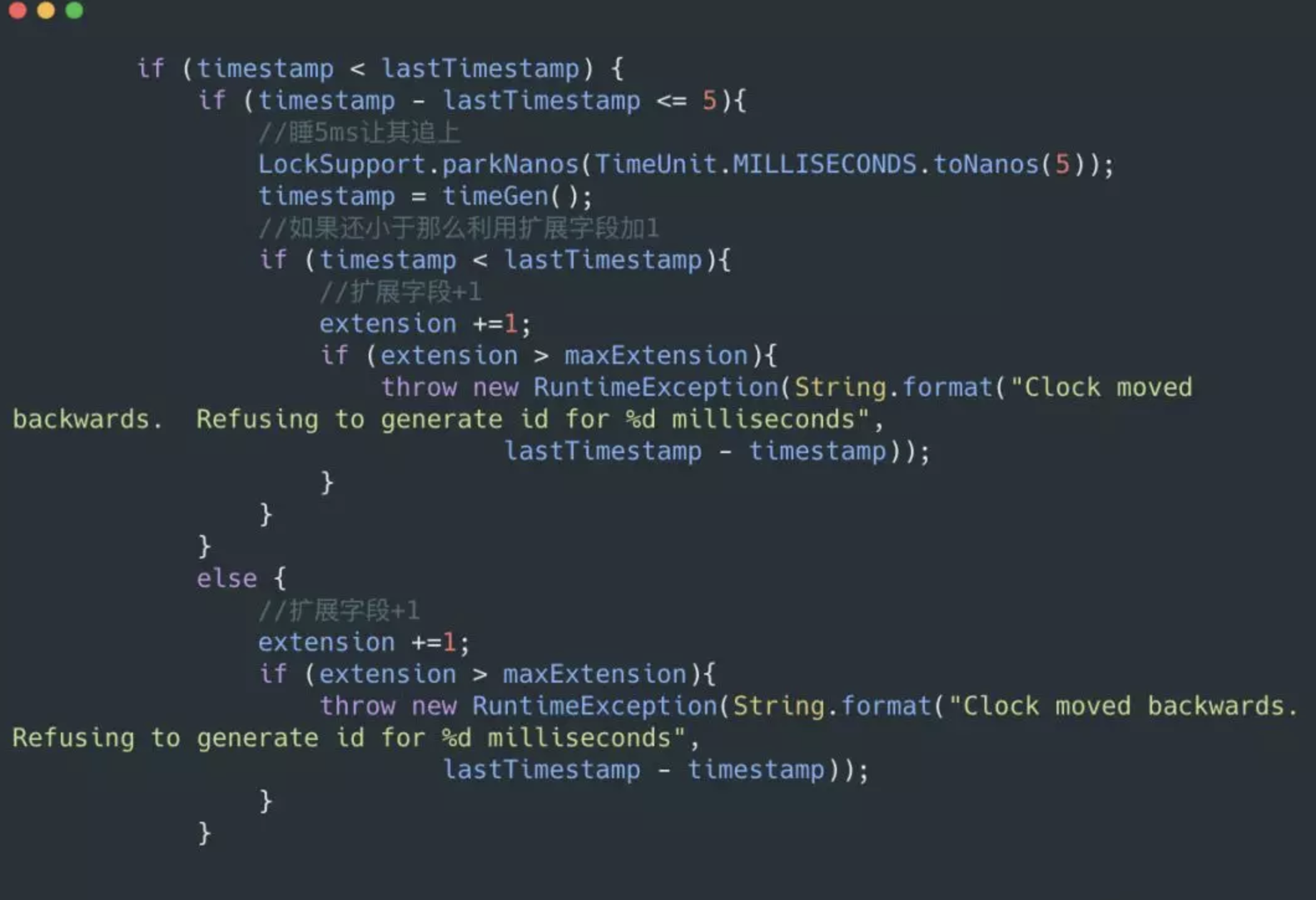
因为机器的原因会发生时间回拨,我们的雪花算法是强依赖我们的时间的,如果时间发生回拨,有可能会生成重复的ID,在我们上面的nextId中我们用当前时间和上一次的时间进行判断,如果当前时间小于上一次的时间那么肯定是发生了回拨,普通的算法会直接抛出异常,这里我们可以对其进行优化,一般分为两个情况:
- 如果时间回拨时间较短,比如配置5ms以内,那么可以直接等待一定的时间,让机器的时间追上来。
- 如果时间的回拨时间较长,我们不能接受这么长的阻塞等待,那么又有两个策略:
- 直接拒绝,抛出异常,打日志,通知RD时钟回滚。
- 利用扩展位,上面我们讨论过不同业务场景位数可能用不到那么多,那么我们可以把扩展位数利用起来了,比如当这个时间回拨比较长的时候,我们可以不需要等待,直接在扩展位加1。2位的扩展位允许我们有3次大的时钟回拨,一般来说就够了,如果其超过三次我们还是选择抛出异常,打日志。
通过上面的几种策略可以比较的防护我们的时钟回拨,防止出现回拨之后大量的异常出现。下面是修改之后的代码,这里修改了时钟回拨的逻辑: