Redis概览
Redis是一款内存高速缓存数据库。Redis全称为:Remote Dictionary Server(远程数据服务. ,Redis是一种支持key-value等多种数据结构的存储系统。可用于缓存,事件发布或订阅,高速队列等场景。支持网络,提供字符串,哈希,列表,队列,集合结构直接存取,基于内存,可持久化。
单线程的redis为什么这么快
- 纯内存操作
- 单线程操作,避免了频繁的上下文切换
- 采用了非阻塞I/O多路复用机制
基础数据类型
Redis所有的key(键. 都是字符串。我们在谈基础数据结构时,讨论的是存储值的数据类型,主要包括常见的5种数据类型,分别是:String、List、Set、Zset、Hash
| 结构类型 | 结构存储的值 | 结构的读写能力 |
|---|---|---|
| String字符串 | 可以是字符串、整数或浮点数 | 对整个字符串或字符串的一部分进行操作;对整数或浮点数进行自增或自减操作; |
| List列表 | 一个链表,链表上的每个节点都包含一个字符串 | 对链表的两端进行push和pop操作,读取单个或多个元素;根据值查找或删除元素; |
| Set集合 | 包含字符串的无序集合 | 字符串的集合,包含基础的方法有看是否存在添加、获取、删除;还包含计算交集、并集、差集等 |
| Hash散列 | 包含键值对的无序散列表 | 包含方法有添加、获取、删除单个元素 |
| Zset有序集合 | 和散列一样,用于存储键值对 | 字符串成员与浮点数分数之间的有序映射;元素的排列顺序由分数的大小决定;包含方法有添加、获取、删除单个元素以及根据分值范围或成员来获取元素 |
持久化
为了防止数据丢失以及服务重启时能够恢复数据,Redis支持数据的持久化,主要分为两种方式,分别是RDB和AOF; 当然实际场景下还会使用这两种的混合模式
RDB 持久化
RDB 就是 Redis DataBase 的缩写,中文名为快照/内存快照,RDB持久化是把当前进程数据生成快照保存到磁盘上的过程,由于是某一时刻的快照,那么快照中的值要早于或者等于内存中的值。
触发方式
手动触发
- save命令:阻塞当前Redis服务器,直到RDB过程完成为止,对于内存 比较大的实例会造成长时间阻塞,线上环境不建议使用
- bgsave命令:Redis进程执行fork操作创建子进程,RDB持久化过程由子进程负责,完成后自动结束。阻塞只发生在fork阶段,一般时间很短
bgsave命令具体流程如下:
- redis客户端执行bgsave命令或者自动触发bgsave命令;
- 主进程判断当前是否已经存在正在执行的子进程,如果存在,那么主进程直接返回;
- 如果不存在正在执行的子进程,那么就fork一个新的子进程进行持久化数据,fork过程是阻塞的,fork操作完成后主进程即可执行其他操作;
- 子进程先将数据写入到临时的rdb文件中,待快照数据写入完成后再原子替换旧的rdb文件;
- 同时发送信号给主进程,通知主进程rdb持久化完成,主进程更新相关的统计信息(info Persitence下的rdb_*相关选项. 。
自动触发
在以下4种情况时会自动触发
- redis.conf中配置save m n,即在m秒内有n次修改时,自动触发bgsave生成rdb文件;
- 主从复制时,从节点要从主节点进行全量复制时也会触发bgsave操作,生成当时的快照发送到从节点;
- 执行debug reload命令重新加载redis时也会触发bgsave操作;
- 默认情况下执行shutdown命令时,如果没有开启aof持久化,那么也会触发bgsave操作;
RDB优缺点
优点
- RDB文件是某个时间节点的快照,默认使用LZF算法进行压缩,压缩后的文件体积远远小于内存大小,适用于备份、全量复制等场景;
- Redis加载RDB文件恢复数据要远远快于AOF方式;
缺点
- RDB方式实时性不够,无法做到秒级的持久化;
- 每次调用bgsave都需要fork子进程,fork子进程属于重量级操作,频繁执行成本较高;
- RDB文件是二进制的,没有可读性,AOF文件在了解其结构的情况下可以手动修改或者补全;
- 版本兼容RDB文件问题;
AOF 持久化
Redis是“写后”日志,Redis先执行命令,把数据写入内存,然后才记录日志。日志里记录的是Redis收到的每一条命令,这些命令是以文本形式保存。PS: 大多数的数据库采用的是写前日志(WAL. ,例如MySQL,通过写前日志和两阶段提交,实现数据和逻辑的一致性。
RDB和AOF混合方式(4.0版本)
Redis 4.0 中提出了一个混合使用 AOF 日志和内存快照的方法。简单来说,内存快照以一定的频率执行,在两次快照之间,使用 AOF 日志记录这期间的所有命令操作。
从持久化中恢复数据
流程如下:
- redis重启时判断是否开启aof,如果开启了aof,那么就优先加载aof文件;
- 如果aof存在,那么就去加载aof文件,加载成功的话redis重启成功,如果aof文件加载失败,那么会打印日志表示启动失败,此时可以去修复aof文件后重新启动;
- 若aof文件不存在,那么redis就会转而去加载rdb文件,如果rdb文件不存在,redis直接启动成功;
- 如果rdb文件存在就会去加载rdb文件恢复数据,如加载失败则打印日志提示启动失败,如加载成功,那么redis重启成功,且使用rdb文件恢复数据;
那么为什么会优先加载AOF呢?因为AOF保存的数据更完整,通过上面的分析我们知道AOF基本上最多损失1s的数据。
Redis事务
Redis 事务的本质是一组命令的集合。事务支持一次执行多个命令,一个事务中所有命令都会被序列化。在事务执行过程,会按照顺序串行化执行队列中的命令,其他客户端提交的命令请求不会插入到事务执行命令序列中。
总结说:redis事务就是一次性、顺序性、排他性的执行一个队列中的一系列命令。
高可用:主从复制
我们知道要避免单点故障,即保证高可用,便需要冗余(副本. 方式提供集群服务。而Redis 提供了主从库模式,以保证数据副本的一致,主从库之间采用的是读写分离的方式。
主从复制,是指将一台Redis服务器的数据,复制到其他的Redis服务器。前者称为主节点(master),后者称为从节点(slave);数据的复制是单向的,只能由主节点到从节点。
- 读操作:主库、从库都可以接收;
- 写操作:首先到主库执行,然后,主库将写操作同步给从库。
主从复制的作用主要包括:
- 数据冗余:主从复制实现了数据的热备份,是持久化之外的一种数据冗余方式。
- 故障恢复:当主节点出现问题时,可以由从节点提供服务,实现快速的故障恢复;实际上是一种服务的冗余。
- 负载均衡:在主从复制的基础上,配合读写分离,可以由主节点提供写服务,由从节点提供读服务(即写Redis数据时应用连接主节点,读Redis数据时应用连接从节点. ,分担服务器负载;尤其是在写少读多的场景下,通过多个从节点分担读负载,可以大大提高Redis服务器的并发量。
- 高可用基石:除了上述作用以外,主从复制还是哨兵和集群能够实施的基础,因此说主从复制是Redis高可用的基础。
主从复制原理
全量复制
当我们启动多个 Redis 实例的时候,它们相互之间就可以通过 replicaof(Redis 5.0 之前使用 slaveof. 命令形成主库和从库的关系,之后会按照三个阶段完成数据的第一次同步。
全量复制

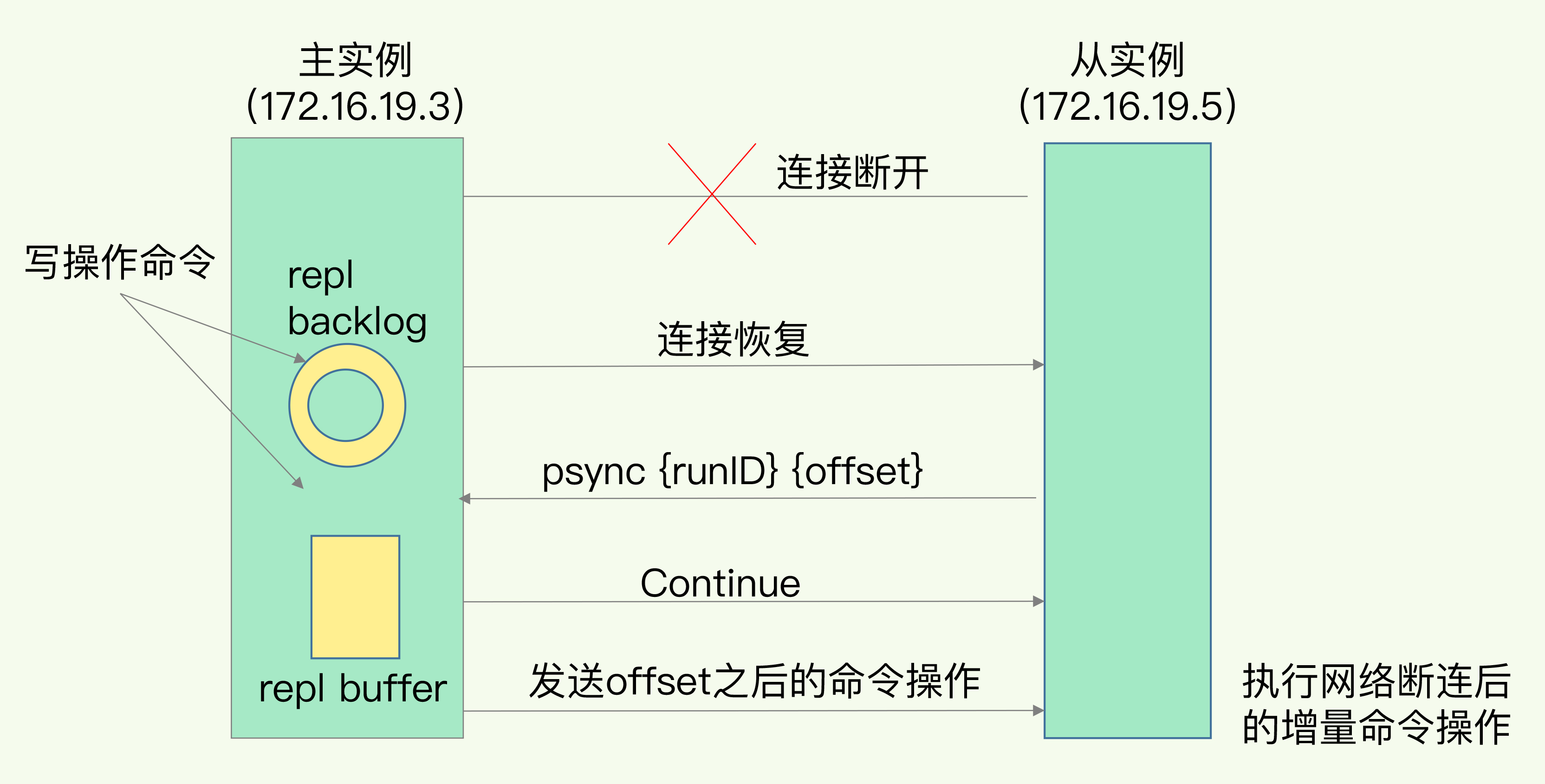
增量复制
高可用:哨兵机制(Redis Sentinel)
如果主节点出现故障该怎么办呢? 在 Redis 主从集群中,哨兵机制是实现主从库自动切换的关键机制,它有效地解决了主从复制模式下故障转移的问题。
主要功能:
- 监控(Monitoring):哨兵会不断地检查主节点和从节点是否运作正常。
- 自动故障转移(Automatic failover):当主节点不能正常工作时,哨兵会开始自动故障转移操作,它会将失效主节点的其中一个从节点升级为新的主节点,并让其他从节点改为复制新的主节点。
- 配置提供者(Configuration provider):客户端在初始化时,通过连接哨兵来获得当前Redis服务的主节点地址。
- 通知(Notification):哨兵可以将故障转移的结果发送给客户端。
高可拓展:分片技术(Redis Cluster)
主从复制和哨兵机制保障了高可用,就读写分离而言虽然slave节点扩展了主从的读并发能力,但是写能力和存储能力是无法进行扩展,就只能是master节点能够承载的上限。如果面对海量数据那么必然需要构建master(主节点分片)之间的集群,同时必然需要牺牲高可用(主从复制和哨兵机制)能力,即每个master分片节点还需要有slave节点,这是分布式系统中典型的纵向扩展(集群的分片技术)的体现;所以在Redis 3.0版本中对应的设计就是Redis Cluster。
方案
- 事前:Redis 高可用,主从+哨兵,Redis cluster,避免全盘崩溃。
- 事中:本地 ehcache 缓存 + Hystrix 限流+降级,避免MySQL被打死。
- 事后:Redis 持久化 RDB+AOF,一旦重启,自动从磁盘上加载数据,快速恢复缓存数据。
最新
主从复制的流程:
1.建立链接;2.rdb全量复制;
2.网络长链接复制。
主-从-从的级联主从复制模式:减少主库的bgsave压力,减少网络传输的压力
断网重连:repl_backlog_size环形缓冲区,存在覆盖情况。
主库还可以根据slave_repl_offset判断是全量复制,还是增量复制