ZooKeeper
简介
- ZooKeeper主要服务于分布式系统,可以用ZooKeeper来做:统一配置管理、统一命名服务、分布式锁、集群管理。
- 使用分布式系统就无法避免对节点管理的问题(需要实时感知节点的状态、对节点进行统一管理等等),而由于这些问题处理起来可能相对麻烦和提高了系统的复杂性,ZooKeeper作为一个能够通用解决这些问题的中间件就应运而生了。
ZooKeeper数据结构
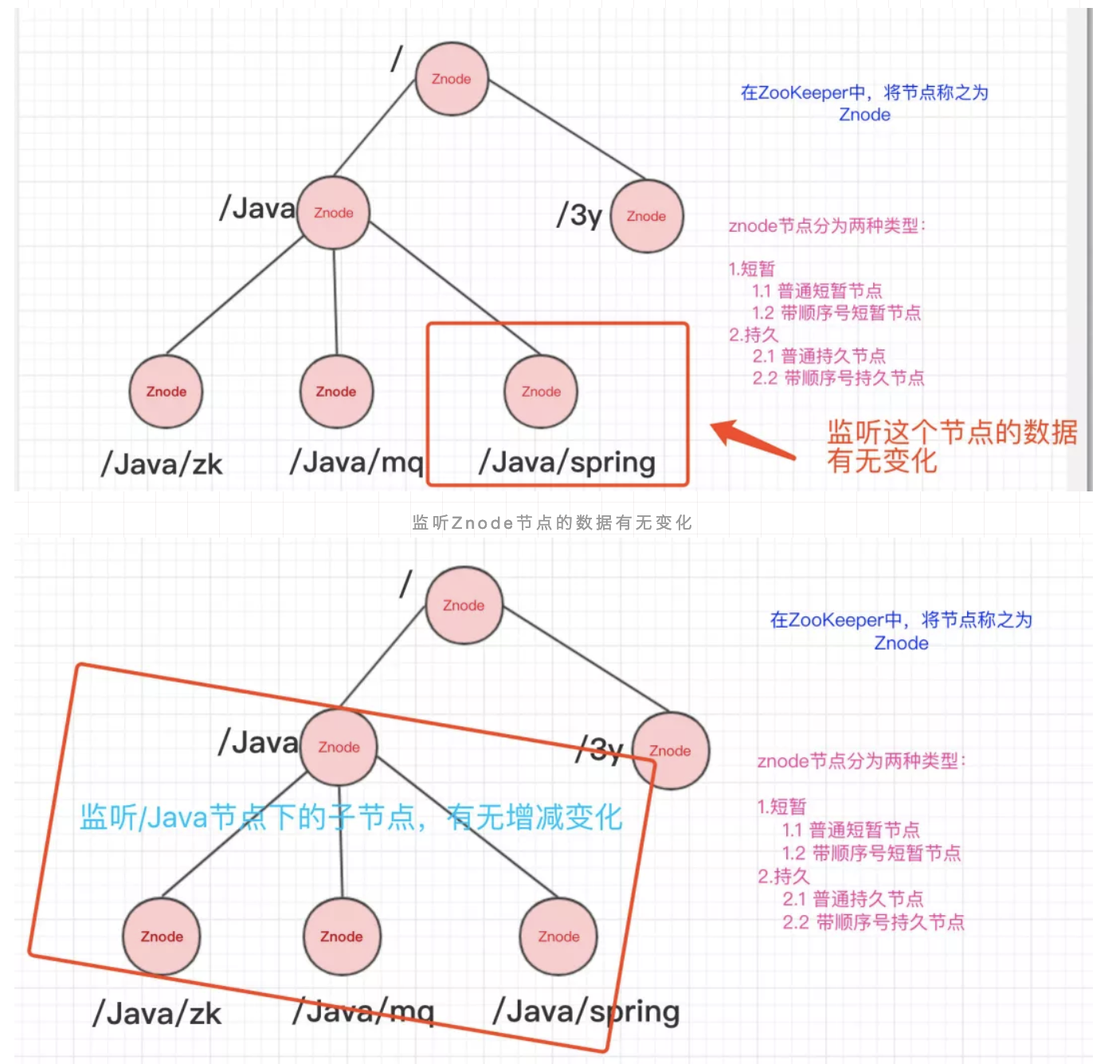
ZooKeeper的数据结构,跟Unix文件系统非常类似,可以看做是一颗树,每个节点叫做ZNode。每一个节点可以通过路径来标识,结构图如下:
- 短暂/临时(Ephemeral):当客户端和服务端断开连接后,所创建的Znode(节点)会自动删除
- 持久(Persistent):当客户端和服务端断开连接后,所创建的Znode(节点)不会删除
监听器
在上面我们已经简单知道了ZooKeeper的数据结构了,ZooKeeper还配合了监听器才能够做那么多事的。 常见的监听场景有以下两项:
- 监听Znode节点的数据变化
- 监听子节点的增减变化
统一配置管理
我们可以将common.yml这份配置放在ZooKeeper的Znode节点中,系统A、B、C监听着这个Znode节点有无变更,如果变更了,及时响应。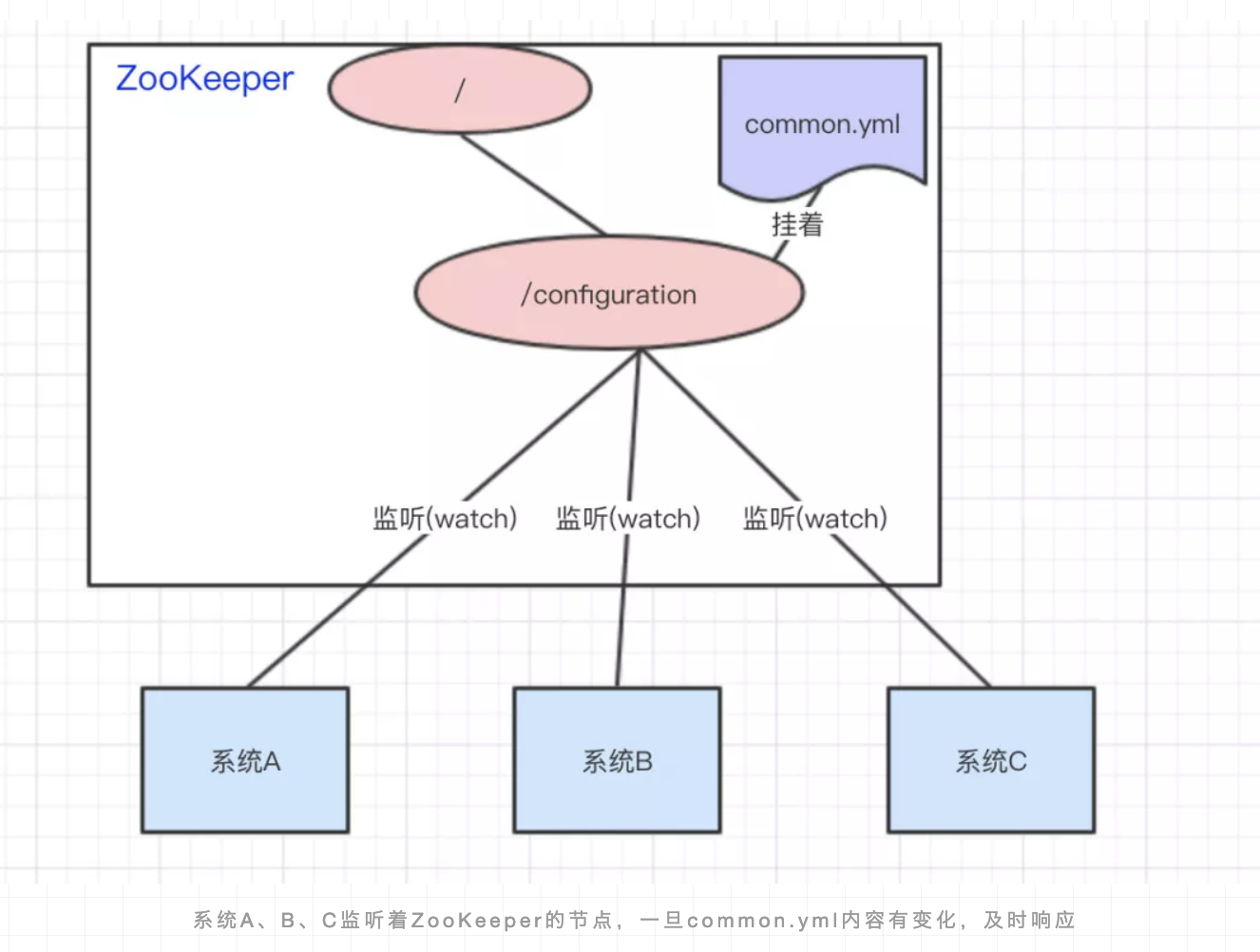
统一命名服务
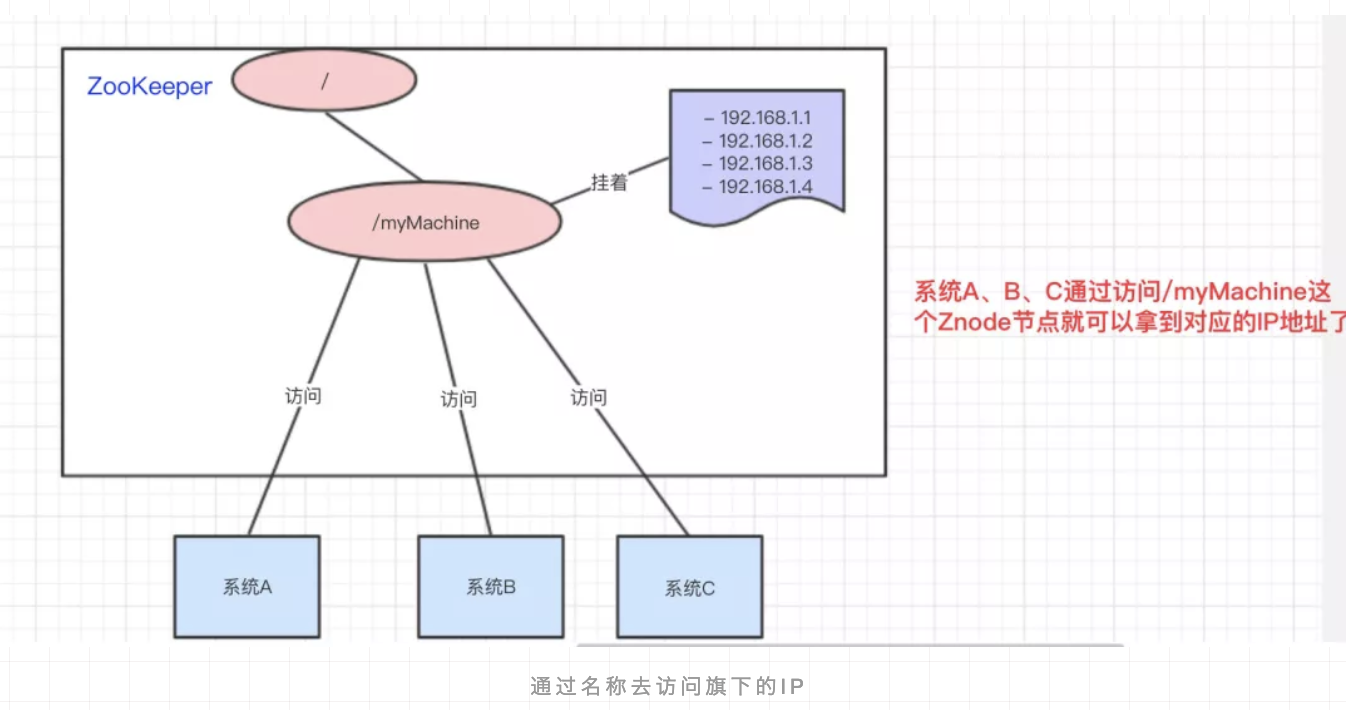
集群管理。
还是以我们三个系统A、B、C为例,在ZooKeeper中创建临时节点即可: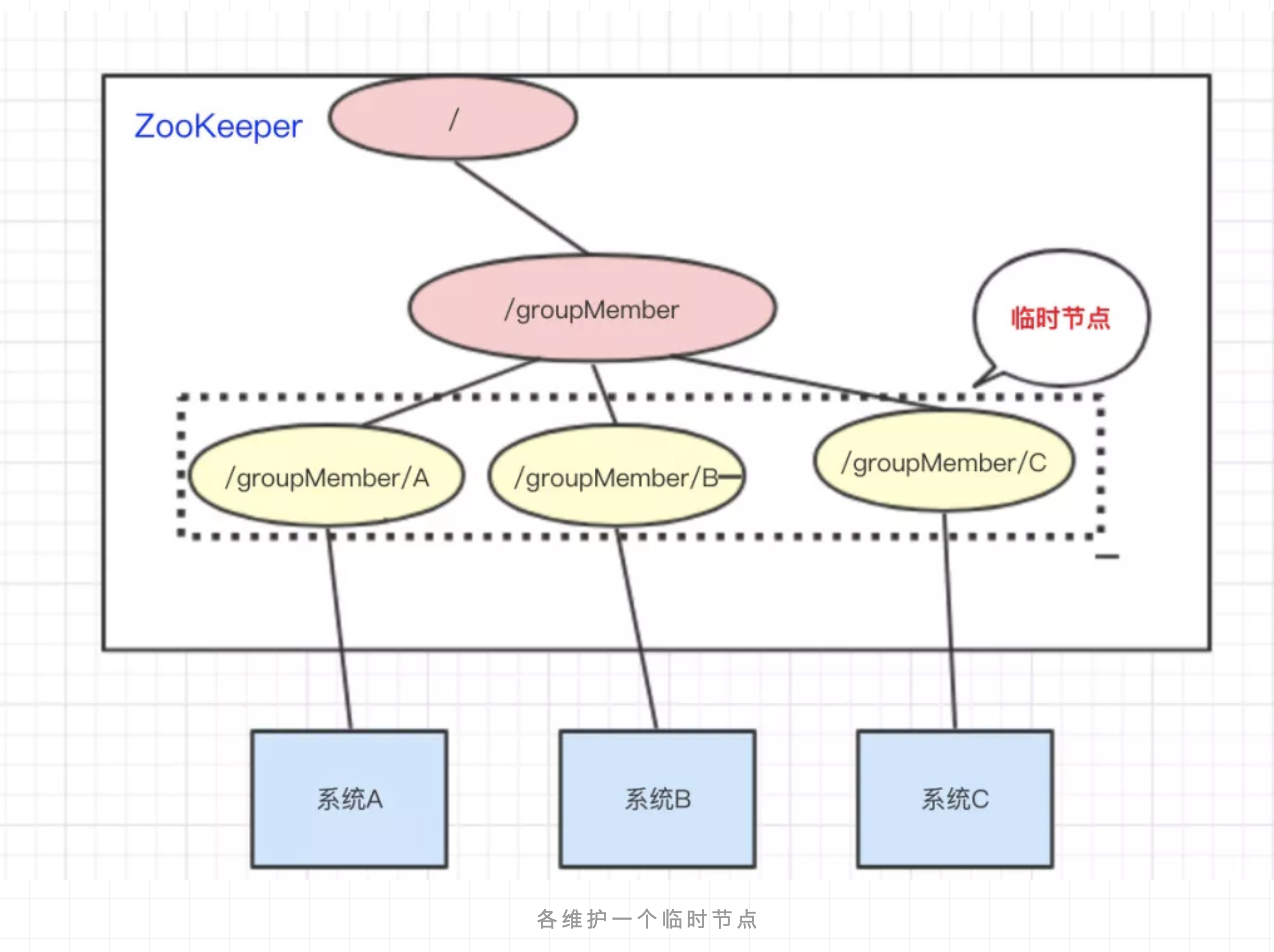
只要系统A挂了,那/groupMember/A这个节点就会删除,通过监听groupMember下的子节点,系统B和C就能够感知到系统A已经挂了。(新增也是同理)
除了能够感知节点的上下线变化,ZooKeeper还可以实现动态选举Master的功能。(如果集群是主从架构模式下)
原理也很简单,如果想要实现动态选举Master的功能,Znode节点的类型是带顺序号的临时节点(EPHEMERAL_SEQUENTIAL)就好了。
- Zookeeper会每次选举最小编号的作为Master,如果Master挂了,自然对应的Znode节点就会删除。然后让新的最小编号作为Master,这样就可以实现动态选举的功能了。
分布式锁
参考分布式锁
ZooKeeper 的一些重要概念
- ZooKeeper 本身就是一个分布式程序(只要半数以上节点存活,ZooKeeper 就能正常服务)。
- 为了保证高可用,最好是以集群形态来部署 ZooKeeper,这样只要集群中大部分机器是可用的(能够容忍一定的机器故障),那么 ZooKeeper 本身仍然是可用的。
- ZooKeeper 将数据保存在内存中,这也就保证了 高吞吐量和低延迟(但是内存限制了能够存储的容量不太大,此限制也是保持znode中存储的数据量较小的进一步原因)。
- ZooKeeper 是高性能的。 在“读”多于“写”的应用程序中尤其地高性能,因为“写”会导致所有的服务器间同步状态。(“读”多于“写”是协调服务的典型场景。)
- ZooKeeper有临时节点的概念。 当创建临时节点的客户端会话一直保持活动,瞬时节点就一直存在。而当会话终结时,瞬时节点被删除。持久节点是指一旦这个ZNode被创建了,除非主动进行ZN 移除操作,否则这个ZNode将一直保存在Zookeeper上。
- ZooKeeper 底层其实只提供了两个功能:
- 管理(存储、读取)用户程序提交的数据;
- 为用户程序提交数据节点监听服务。
可构建集群
为了保证高可用,最好是以集群形态来部署 ZooKeeper,这样只要集群中大部分机器是可用的(能够容忍一定的机器故障),那么zookeeper本身仍然是可用的。 客户端在使用 ZooKeeper 时,需要知道集群机器列表,通过与集群中的某一台机器建立 TCP 连接来使用服务,客户端使用这个TCP链接来发送请求、获取结果、获取监听事件以及发送心跳包。如果这个连接异常断开了,客户端可以连接到另外的机器上。
ZooKeeper 官方提供的架构图: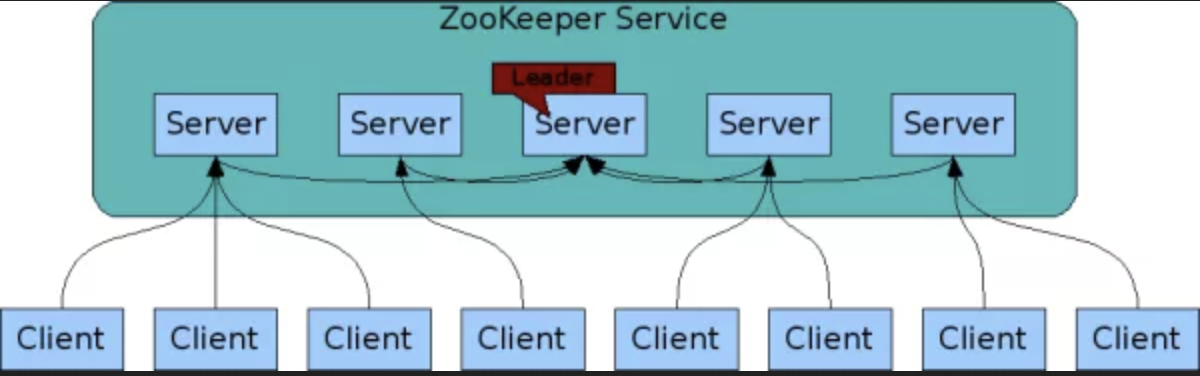
ZooKeeper 集群角色介绍
最典型集群模式: Master/Slave 模式(主备模式)。在这种模式中,通常 Master服务器作为主服务器提供写服务,其他的 Slave 服务器从服务器通过异步复制的方式获取 Master 服务器最新的数据提供读服务。
但是,在 ZooKeeper 中没有选择传统的 Master/Slave 概念,而是引入了Leader、Follower 和 Observer 三种角色。如下图所示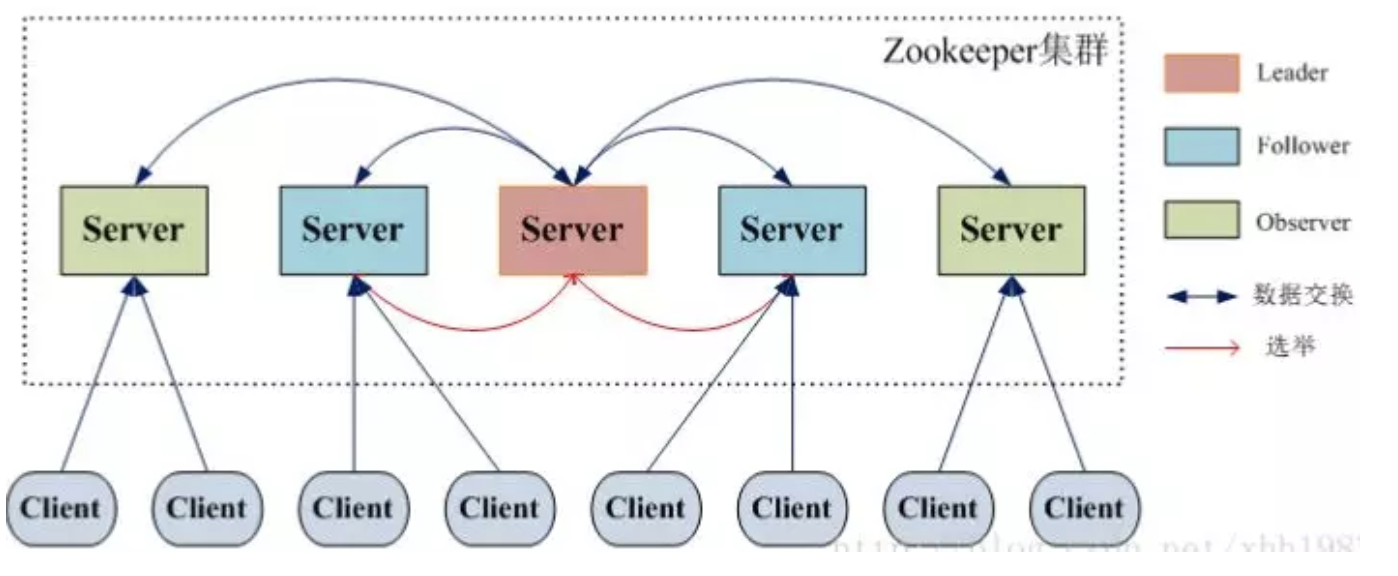
ZooKeeper 集群中的所有机器通过一个 Leader 选举过程来选定一台称为 “Leader” 的机器,Leader 既可以为客户端提供写服务又能提供读服务。除了 Leader 外,Follower 和 Observer 都只能提供读服务。Follower 和 Observer 唯一的区别在于 Observer 机器不参与 Leader 的选举过程,也不参与写操作的“过半写成功”策略,因此 Observer 机器可以在不影响写性能的情况下提升集群的读性能。
为什么最好使用奇数台服务器构成 ZooKeeper 集群
我们知道在Zookeeper中 Leader 选举算法采用了Zab协议。Zab核心思想是当多数 Server 写成功,则任务数据写成功。
- 如果有3个Server,则最多允许1个Server 挂掉。
- 如果有4个Server,则同样最多允许1个Server挂掉。
- 既然3个或者4个Server,同样最多允许1个Server挂掉,那么它们的可靠性是一样的,所以选择奇数个ZooKeeper Server即可,这里选择3个Server。
ZooKeeper &ZAB 协议&Paxos算法
Paxos 算法应该可以说是 ZooKeeper 的灵魂了。但是,ZooKeeper 并没有完全采用 Paxos算法 ,而是使用 ZAB 协议作为其保证数据一致性的核心算法。另外,在ZooKeeper的官方文档中也指出,ZAB协议并不像 Paxos 算法那样,是一种通用的分布式一致性算法,它是一种特别为Zookeeper设计的崩溃可恢复的原子消息广播算法。
ZAB 协议介绍
ZAB(ZooKeeper Atomic Broadcast 原子广播) 协议是为分布式协调服务 ZooKeeper 专门设计的一种支持崩溃恢复的原子广播协议。 在 ZooKeeper 中,主要依赖 ZAB 协议来实现分布式数据一致性,基于该协议,ZooKeeper 实现了一种主备模式的系统架构来保持集群中各个副本之间的数据一致性。
ZAB 协议两种基本的模式:崩溃恢复和消息广播
ZAB协议包括两种基本的模式,分别是崩溃恢复和消息广播。当整个服务框架在启动过程中,或是当 Leader 服务器出现网络中断、崩溃退出与重启等异常情况时,ZAB 协议就会进人恢复模式并选举产生新的Leader服务器。当选举产生了新的 Leader 服务器,同时集群中已经有过半的机器与该Leader服务器完成了状态同步之后,ZAB协议就会退出恢复模式。其中,所谓的状态同步是指数据同步,用来保证集群中存在过半的机器能够和Leader服务器的数据状态保持一致。
**当集群中已经有过半的Follower服务器完成了和Leader服务器的状态同步,那么整个服务框架就可以进人消息广播模式了。**当一台同样遵守ZAB协议的服务器启动后加人到集群中时,如果此时集群中已经存在一个Leader服务器在负责进行消息广播,那么新加人的服务器就会自觉地进人数据恢复模式:找到Leader所在的服务器,并与其进行数据同步,然后一起参与到消息广播流程中去。正如上文介绍中所说的,ZooKeeper设计成只允许唯一的一个Leader服务器来进行事务请求的处理。Leader服务器在接收到客户端的事务请求后,会生成对应的事务提案并发起一轮广播协议;而如果集群中的其他机器接收到客户端的事务请求,那么这些非Leader服务器会首先将这个事务请求转发给Leader服务器。
关于 ZAB 协议&Paxos算法 需要讲和理解的东西太多了,说实话,笔主到现在不太清楚这俩兄弟的具体原理和实现过程。推荐阅读下面两篇文章:
关于如何使用 zookeeper 实现分布式锁,可以查看下面这篇文章: